Are you using top-k wrong in LLM API 😱 . Here’s why that’s killing your generations.
✨ Part 4/ 5 of The Creative Shell – What Makes LLMs “Creative”? (see part 3 here)
So, we’ve seen Temperature 🔥and top-p 🔝 so far!
Now we meet the third filter in our creativity toolkit: the “TOP-K”.
Here’s what top-k actually does 👇
“Only consider the K most likely tokens. Delete everything else.”
-Wait! did you say “Delete everything else”? 😱
-Yup!
Top-k = 25 means:
→ Take the 25 highest-probability tokens
→ Set everything else to zero
…
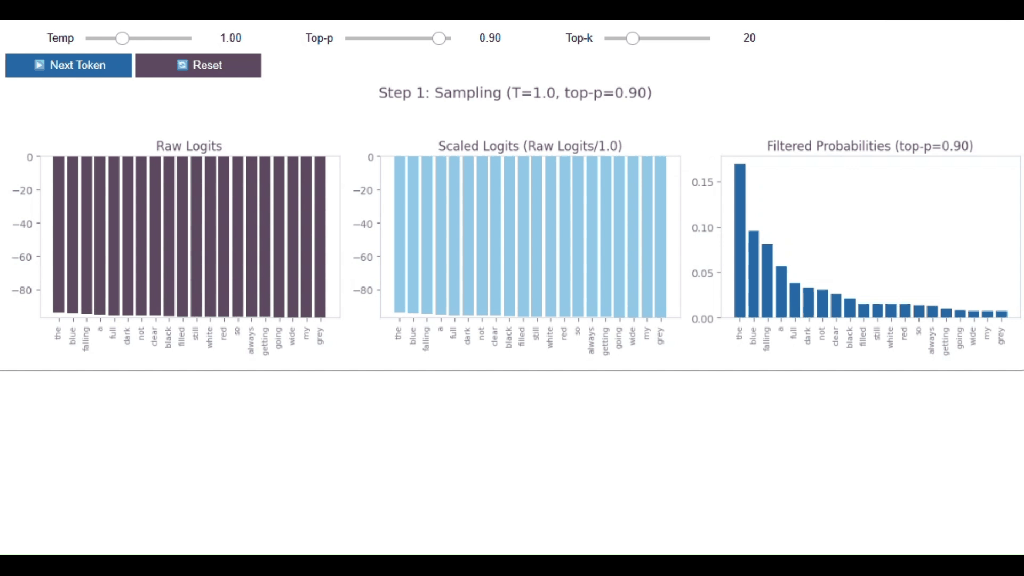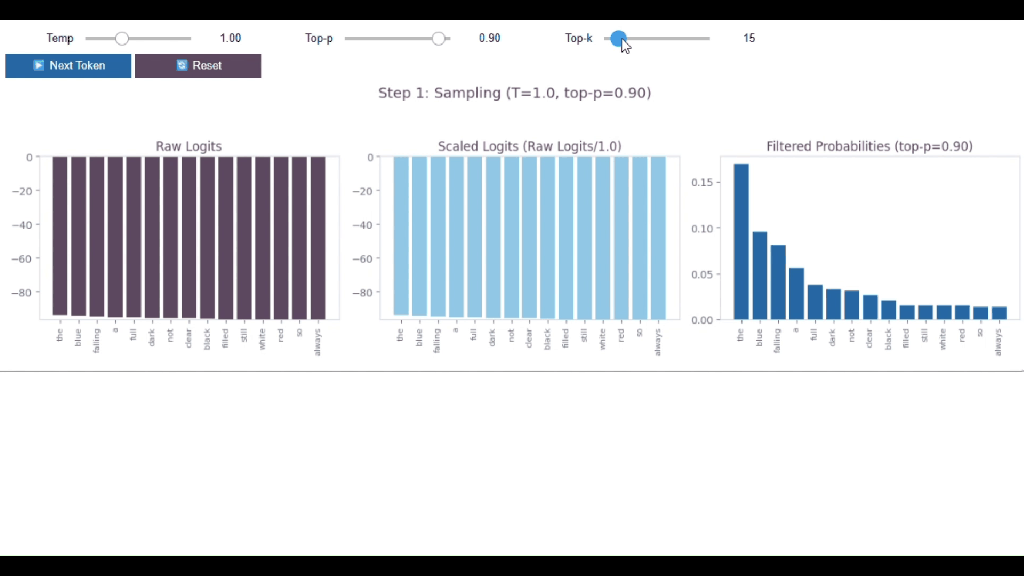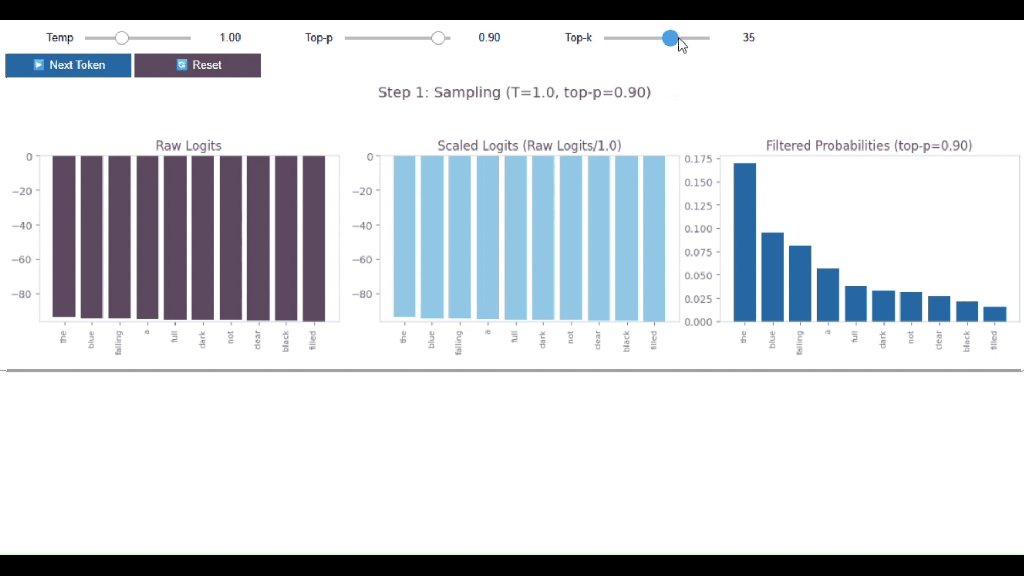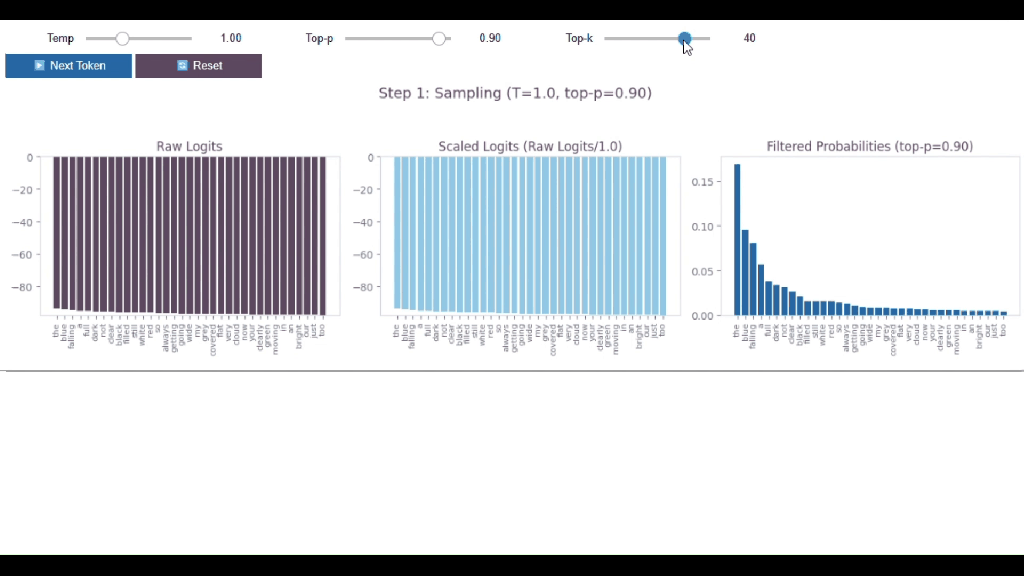
So, before applying Top-k, there were 50,000 possible words
After applying Top-k, it is just 25!
The other 49,975? Gone. 😱
Let’s compare the big two filters:
➡️ TOP-K (rigid + blind), it always uses exactly K tokens and ignores the probability distribution
🤔 99% confident? Still picks K tokens 😵
🤔Uncertain? Still picks K tokens 😵
➡️ TOP-P (adaptive + aware)
Picks however many tokens reach P% of total probability, and follows the distribution
🤓 Confident → few tokens 😎
🤔 Uncertain → many tokens 😎
That does not mean we should not use TOP-K at all, use it when:
👉 You have a fixed “creativity budget” especially when working with smaller models – These often have flatter probability distributions, so top-k prevents the model from wandering into low-quality tokens while keeping enough options.
Tomorrow: The finale 🤩 How to apply these tricks beyond LLMs.
(Hint: it matters for more than just chatbots.)
